SQL: 두 판 사이의 차이
IT 위키
(새 문서: 분류:데이터베이스분류:정보처리기사 ;Structured Query Language ;관계형 데이터베이스의 데이터를 관리하기 위해 설계된 특수 목적의...) |
편집 요약 없음 |
||
| (사용자 8명의 중간 판 20개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
[[분류:데이터베이스]][[분류:정보처리기사]] | [[분류:데이터베이스]] | ||
[[분류:정보처리기사]] | |||
;Structured Query Language | ;Structured Query Language | ||
;[[관계형 데이터베이스]]의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어 | ;[[관계형 데이터베이스]]의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어 | ||
== 역사 == | ==역사== | ||
* 관계형 데이터베이스의 튜플 해석 이론을 기반으로 만들어졌다. | |||
* 1970년대 초 IBM의 도널드 D. 챔벌린과 레이먼드 F. 보이스가 개발하였다. | *관계형 데이터베이스의 튜플 해석 이론을 기반으로 만들어졌다. | ||
* 현재는 대부분의 [[관계형 데이터베이스]] [[DBMS|시스템]]에서 표준으로 채택해 사용하고 있다. | *1970년대 초 IBM의 도널드 D. 챔벌린과 레이먼드 F. 보이스가 개발하였다. | ||
*현재는 대부분의 [[관계형 데이터베이스]] [[DBMS|시스템]]에서 표준으로 채택해 사용하고 있다. | |||
*ANSI와 ISO의 공동작업에 의해 지속적으로 발전하고 있다. | |||
**SQL-86, SQL-89, SQL-92, SQL-99, SQL-2003, SQL-2011 등 | |||
**그러나 대부분의 DBMS는 표준을 정확히 따르기 보단 자사 특유의 문법을 같이 활용한다. | |||
==특징== | |||
*비절차적 언어 | |||
*관계형 언어 | |||
==구분== | |||
;SQL은 DDL, DML, DCL 3가지로 구분 가능 | |||
;[[파일:SQL 분류.png|700x700픽셀]] | |||
===[[DDL|데이터 정의 언어(DDL)]]=== | |||
;Data Definition Language | |||
*DB(Schema), Table, View, Index 등을 정의(생성·갱신·삭제)할 때 쓰인다. | |||
*대표적인 명령: CREATE, ALTER, DROP | |||
===[[DML|데이터 조작 언어(DML)]]=== | |||
;Data Manipulation Language | |||
*테이블의 데이터를 조회하고 조작(삽입·갱신·삭제)할 때 쓰인다. | |||
*대표적 명령: SELECT, INSERT, DELETE, UPDATE | |||
===[[DCL|데이터 제어 언어(DCL)]]=== | |||
;Data Control Language | |||
*데이터의 보안, 무결성, 등을 위해 쓰인다. | |||
*대표적 명령: GRANT, REVOKE | |||
== | === [[트랜잭션 제어 언어|트랜잭션 제어 언어(TCL)]] === | ||
'''Transaction Control Language''' | |||
*[[데이터베이스 병행제어|트랜잭션 병행제어]]를 위해 사용된다. | |||
*대표적 명령: COMMIT, ROLLBACK | |||
==용법== | |||
===데이터 정의 언어(DDL)=== | ===데이터 정의 언어(DDL)=== | ||
; | ====CREATE 구문==== | ||
* | |||
* | ;스키마, 도메인, 테이블, 뷰, 인덱스를 정의할 때 사용 | ||
;*인덱스 생성 | |||
;**CREATE INDEX index_name ON table_name(column1, column2,...); | |||
====ALTER 구문==== | |||
;스키마, 도메인, 테이블, 뷰, 인덱스를 수정할 때 사용 | |||
*뷰 수정 | |||
**ALTER VIEW [대상 뷰] AS SELECT [대상 필드] FROM [대상 테이블] | |||
====DROP 구문==== | |||
;스키마, 도메인, 테이블, 뷰, 인덱스를 삭제할 때 사용 | |||
*뷰 삭제 | |||
**DROP VIEW [대상 뷰] | |||
===데이터 조작 언어(DML)=== | ===데이터 조작 언어(DML)=== | ||
; | ====SELECT 구문==== | ||
* | |||
* | ;테이블의 데이터를 조회·검색할 때 사용 | ||
*SELECT [조회할 속성] FROM [조회 대상 테이블] WHERE [조회 조건] | |||
*'''SELECT 조회할 속성''' | |||
**속성을 따옴표로 나열하여서 적는다. | |||
***SELECT 이름, 나이 FROM 학생 | |||
**모든 속성에 대해 조회하려면 * 을 적는다. (* 는 'all'이라 읽음) | |||
***SELECT * FROM 학생 ('셀렉트 올 프럼 학생' 이라고 읽음) | |||
*'''FROM 조회 대상 테이블''' | |||
**조회 대상 테이블을 따옴표로 나열하여 적는다. | |||
*'''WHERE 조회 조건''' | |||
**일치하는 조건을 찾을 때는 '''속성 = '값''''으로 적는다. | |||
***ex) SELECT * FROM 학생 WHERE 이름 = '홍길동' | |||
**크거나 작은 조건을 찾을 때는 '''>, <, <=, >='''와 같이 부등호를 사용한다. | |||
***ex) SELECT * FROM 학생 WHERE 나이 > '11살' | |||
**다름을 표현할 때는 '''!=''' 또는 '''<>''' 를 사용한다. | |||
***ex) SELECT * FROM 학생 WHERE 나이 <> '11살' | |||
**단, NULL이 아님을 표현 할 때는 '<nowiki/>'''IS NOT NULL'''' 이라고 적는다. | |||
***ex) SELECT * FROM 학생 WHERE 직업 IS NOT NULL | |||
**비슷함을 표현할 때는 '''LIKE와 %'''를 사용한다. | |||
***%는 WILD CARD로, %가 위치한 곳은 어떤 문자열도 올수 있다. | |||
***ex) SELECT * FROM 학생 WHERE 이름 LIKE '홍% | |||
**조건이 여러개일 때는 '''AND나 OR'''로 잇고 '''괄호'''를 사용할 수 있다. | |||
***ex) SELECT * FROM 학생 WHERE 이름 = '홍길동' AND (나이 <= '19' OR 직업 = '학생') | |||
====INSERT 구문==== | |||
;테이블의 데이터를 삽입할 때 사용 | |||
====DELETE 구문==== | |||
;테이블의 데이터를 삭제할 때 사용 | |||
====UPDATE 구문==== | |||
;테이블의 데이터를 갱신할 때 사용 | |||
*UPDATE [갱신 대상 테이블] SET [갱신할 속성] = [갱신 값] WHERE [검색 조건] | |||
===데이터 제어 언어(DCL)=== | ===데이터 제어 언어(DCL)=== | ||
; | ====COMMIT==== | ||
* | ====ROLLBACK==== | ||
* | '''commit 을 취소 하기 위해 사용''' | ||
이전에 실행된 commit 을 취소하고 commit 이전 상태로 트랜잭션을 되돌리는것 | |||
====GRANT==== | |||
;권한을 부여할 때 사용 | |||
*GRANT [행위] ON [대상] TO [사용자] | |||
**ex) GRANT SELECT, INSERT, UPDATE dbname.* TO testuser@localhost identified by 'password' | |||
**ex) GRANT ALL PRIVILEGES ON *.* TO testuser@"%" identified by 'password' | |||
====REVOKE==== | |||
;권한을 회수할 때 사용 | |||
*REVOKE [행위] ON [대상] FROM [사용자] | |||
**ex) REVOKE SELECT, INSERT, UPDATE dbname.* FROM testuser@localhost | |||
**ex) REVOKE ALL ON *.* FROM testuser@"%" | |||
==함수== | |||
===집계 함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
|- | |||
|SUM | |||
|대상 칼럼의 모든 값을 더함 | |||
|- | |||
|AVG | |||
|대상 칼럼의 평균을 계산 | |||
|- | |||
|MIN | |||
|대상 칼럼의 값 중 가장 작은 값 선택 | |||
|- | |||
|MAX | |||
|대상 칼럼의 값 중 가장 큰 값 선택 | |||
|- | |||
|COUNT | |||
|대상 칼럼의 값의 갯수를 카운트 | |||
|} | |||
===대소문자 변환함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!사용예 | |||
|- | |||
|INITCAP | |||
|문자열의 첫번째 문자만 대문자로 변환 | |||
|INITCAP(student) -> Student | |||
|- | |||
|LOWER | |||
|문자열 전체를 소문자로 변환 | |||
|LOWER(ABC) -> abc | |||
|- | |||
|UPPER | |||
|문자열 전체를 대문자로 변환 | |||
|UPPER(abc) -> ABC | |||
|} | |||
===문자열 길이 반환함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!사용예 | |||
|- | |||
|LENGTH | |||
|문자열의 길이를 반환 | |||
|LENGTH('홍길동') -> 3 | |||
|- | |||
|LENGTHB | |||
|문자열의 바이트 수를 반환 | |||
|LENGTHB('홍길동') -> 6 | |||
|} | |||
===문자 조작 함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!사용예 | |||
|- | |||
|CONCAT | |||
|<nowiki>두 문자열을 결합. ||와 동일</nowiki> | |||
|CONCAT('sql','plus') -> sqlplus | |||
|- | |||
|SUBSTR | |||
|특정 문자 또는 문자열 일부를 추출 | |||
|SUBSTR('SQL*PLUS',5,4) -> PLUS | |||
|- | |||
|INSTR | |||
|특정 문자가 출현하는 첫번째 위치 반환 | |||
|INSTR('SQL*Plus','*',1,1) -> 4 | |||
|- | |||
|LPAD | |||
|오른쪽 정렬 후 왼쪽에 지정한 문자 삽입 | |||
|LPAD('sql',5,'*') -> **sql | |||
|- | |||
|RPAD | |||
|왼쪽 정렬 후 오른쪽에 지정한 문자 삽입 | |||
|RPAD('sql',5,'*') -> sql** | |||
|- | |||
|LTRIM | |||
|왼쪽의 지정 문자를 삭제 | |||
|LTRIM('*sql','*') -> sql | |||
|- | |||
|RTRIM | |||
|오른쪽의 지정 문자를 삭제 | |||
|RTRIM('sql*','*') -> sql | |||
|} | |||
===숫자 함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!사용예 | |||
|- | |||
|ROUND | |||
|지정한 자리 이하에서 반올림 | |||
|ROUND(123.17,1) -> 123.2 | |||
|- | |||
|TRUNC | |||
|지정한 자리 이하에서 절삭(버림) | |||
|TRUNC(123.17,1) -> 123.1 | |||
|- | |||
|MOD(m, n) | |||
|m을 n으로 나눈 나머지 값 | |||
|MOD(12,10) -> 2 | |||
|- | |||
|CEIL | |||
|지정한 값보다 큰 수 중에서 가장 작은 정수 | |||
|CEIL(123.17) -> 124 | |||
|- | |||
|FLOOR | |||
|지정한 값보다 작은 수 중에서 가장 큰 정수 | |||
|FLOOR(123.17) -> 123 | |||
|} | |||
===날짜 함수=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!결과 | |||
|- | |||
|SYSDATE | |||
|시스템의 현재 날짜 | |||
|날짜 | |||
|- | |||
|MONTHS_BETWEEN | |||
|날짜와 날짜 사이의 개월을 계산 | |||
|숫자 | |||
|- | |||
|ADD_MONTHS | |||
|날짜에 개월을 더한 날짜 계산 | |||
|날짜 | |||
|- | |||
|NEXT_DAY | |||
|날짜 후의 첫 월요일 날짜를 계산 | |||
|날짜 | |||
|- | |||
|LAST_DAY | |||
|월의 마지막 날짜를 계산 | |||
|날짜 | |||
|- | |||
|ROUND | |||
|날짜를 반올림 | |||
|날짜 | |||
|- | |||
|TRUNC | |||
|날짜를 절삭 | |||
|날짜 | |||
|} | |||
===형변환=== | |||
{| class="wikitable" | |||
!종류 | |||
!의미 | |||
!사용예 | |||
!결과 | |||
|- | |||
|TO_CHAR | |||
|숫자, 날짜를 문자타입으로 | |||
|TO_CHAR('07-12', 'YYYY-MM') | |||
|2007-12 | |||
|- | |||
|TO_NUMBER | |||
|문자열을 숫자타입으로 | |||
|TO_NUMBER('1000') | |||
|1,000 | |||
|- | |||
|TO_DATE | |||
|문자열을 날짜타입으로 | |||
|TO_DATE('05/03', 'YYYY-MM') | |||
|0005-03 | |||
|} | |||
<br /> | |||
2024년 10월 13일 (일) 00:41 기준 최신판
- Structured Query Language
- 관계형 데이터베이스의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어
역사[편집 | 원본 편집]
- 관계형 데이터베이스의 튜플 해석 이론을 기반으로 만들어졌다.
- 1970년대 초 IBM의 도널드 D. 챔벌린과 레이먼드 F. 보이스가 개발하였다.
- 현재는 대부분의 관계형 데이터베이스 시스템에서 표준으로 채택해 사용하고 있다.
- ANSI와 ISO의 공동작업에 의해 지속적으로 발전하고 있다.
- SQL-86, SQL-89, SQL-92, SQL-99, SQL-2003, SQL-2011 등
- 그러나 대부분의 DBMS는 표준을 정확히 따르기 보단 자사 특유의 문법을 같이 활용한다.
특징[편집 | 원본 편집]
- 비절차적 언어
- 관계형 언어
구분[편집 | 원본 편집]
- SQL은 DDL, DML, DCL 3가지로 구분 가능
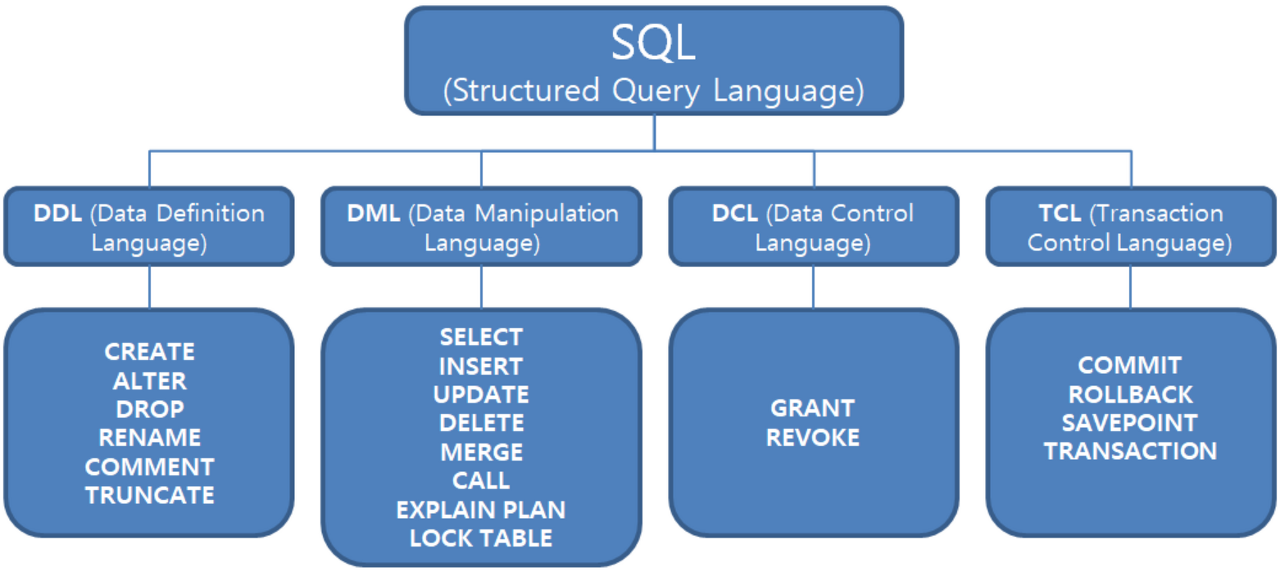

데이터 정의 언어(DDL)[편집 | 원본 편집]
- Data Definition Language
- DB(Schema), Table, View, Index 등을 정의(생성·갱신·삭제)할 때 쓰인다.
- 대표적인 명령: CREATE, ALTER, DROP
데이터 조작 언어(DML)[편집 | 원본 편집]
- Data Manipulation Language
- 테이블의 데이터를 조회하고 조작(삽입·갱신·삭제)할 때 쓰인다.
- 대표적 명령: SELECT, INSERT, DELETE, UPDATE
데이터 제어 언어(DCL)[편집 | 원본 편집]
- Data Control Language
- 데이터의 보안, 무결성, 등을 위해 쓰인다.
- 대표적 명령: GRANT, REVOKE
트랜잭션 제어 언어(TCL)[편집 | 원본 편집]
Transaction Control Language
- 트랜잭션 병행제어를 위해 사용된다.
- 대표적 명령: COMMIT, ROLLBACK
용법[편집 | 원본 편집]
데이터 정의 언어(DDL)[편집 | 원본 편집]
CREATE 구문[편집 | 원본 편집]
- 스키마, 도메인, 테이블, 뷰, 인덱스를 정의할 때 사용
- 인덱스 생성
- CREATE INDEX index_name ON table_name(column1, column2,...);
ALTER 구문[편집 | 원본 편집]
- 스키마, 도메인, 테이블, 뷰, 인덱스를 수정할 때 사용
- 뷰 수정
- ALTER VIEW [대상 뷰] AS SELECT [대상 필드] FROM [대상 테이블]
DROP 구문[편집 | 원본 편집]
- 스키마, 도메인, 테이블, 뷰, 인덱스를 삭제할 때 사용
- 뷰 삭제
- DROP VIEW [대상 뷰]
데이터 조작 언어(DML)[편집 | 원본 편집]
SELECT 구문[편집 | 원본 편집]
- 테이블의 데이터를 조회·검색할 때 사용
- SELECT [조회할 속성] FROM [조회 대상 테이블] WHERE [조회 조건]
- SELECT 조회할 속성
- 속성을 따옴표로 나열하여서 적는다.
- SELECT 이름, 나이 FROM 학생
- 모든 속성에 대해 조회하려면 * 을 적는다. (* 는 'all'이라 읽음)
- SELECT * FROM 학생 ('셀렉트 올 프럼 학생' 이라고 읽음)
- 속성을 따옴표로 나열하여서 적는다.
- FROM 조회 대상 테이블
- 조회 대상 테이블을 따옴표로 나열하여 적는다.
- WHERE 조회 조건
- 일치하는 조건을 찾을 때는 속성 = '값'으로 적는다.
- ex) SELECT * FROM 학생 WHERE 이름 = '홍길동'
- 크거나 작은 조건을 찾을 때는 >, <, <=, >=와 같이 부등호를 사용한다.
- ex) SELECT * FROM 학생 WHERE 나이 > '11살'
- 다름을 표현할 때는 != 또는 <> 를 사용한다.
- ex) SELECT * FROM 학생 WHERE 나이 <> '11살'
- 단, NULL이 아님을 표현 할 때는 'IS NOT NULL' 이라고 적는다.
- ex) SELECT * FROM 학생 WHERE 직업 IS NOT NULL
- 비슷함을 표현할 때는 LIKE와 %를 사용한다.
- %는 WILD CARD로, %가 위치한 곳은 어떤 문자열도 올수 있다.
- ex) SELECT * FROM 학생 WHERE 이름 LIKE '홍%
- 조건이 여러개일 때는 AND나 OR로 잇고 괄호를 사용할 수 있다.
- ex) SELECT * FROM 학생 WHERE 이름 = '홍길동' AND (나이 <= '19' OR 직업 = '학생')
- 일치하는 조건을 찾을 때는 속성 = '값'으로 적는다.
INSERT 구문[편집 | 원본 편집]
- 테이블의 데이터를 삽입할 때 사용
DELETE 구문[편집 | 원본 편집]
- 테이블의 데이터를 삭제할 때 사용
UPDATE 구문[편집 | 원본 편집]
- 테이블의 데이터를 갱신할 때 사용
- UPDATE [갱신 대상 테이블] SET [갱신할 속성] = [갱신 값] WHERE [검색 조건]
데이터 제어 언어(DCL)[편집 | 원본 편집]
COMMIT[편집 | 원본 편집]
ROLLBACK[편집 | 원본 편집]
commit 을 취소 하기 위해 사용
이전에 실행된 commit 을 취소하고 commit 이전 상태로 트랜잭션을 되돌리는것
GRANT[편집 | 원본 편집]
- 권한을 부여할 때 사용
- GRANT [행위] ON [대상] TO [사용자]
- ex) GRANT SELECT, INSERT, UPDATE dbname.* TO testuser@localhost identified by 'password'
- ex) GRANT ALL PRIVILEGES ON *.* TO testuser@"%" identified by 'password'
REVOKE[편집 | 원본 편집]
- 권한을 회수할 때 사용
- REVOKE [행위] ON [대상] FROM [사용자]
- ex) REVOKE SELECT, INSERT, UPDATE dbname.* FROM testuser@localhost
- ex) REVOKE ALL ON *.* FROM testuser@"%"
함수[편집 | 원본 편집]
집계 함수[편집 | 원본 편집]
| 종류 | 의미 |
|---|---|
| SUM | 대상 칼럼의 모든 값을 더함 |
| AVG | 대상 칼럼의 평균을 계산 |
| MIN | 대상 칼럼의 값 중 가장 작은 값 선택 |
| MAX | 대상 칼럼의 값 중 가장 큰 값 선택 |
| COUNT | 대상 칼럼의 값의 갯수를 카운트 |
대소문자 변환함수[편집 | 원본 편집]
| 종류 | 의미 | 사용예 |
|---|---|---|
| INITCAP | 문자열의 첫번째 문자만 대문자로 변환 | INITCAP(student) -> Student |
| LOWER | 문자열 전체를 소문자로 변환 | LOWER(ABC) -> abc |
| UPPER | 문자열 전체를 대문자로 변환 | UPPER(abc) -> ABC |
문자열 길이 반환함수[편집 | 원본 편집]
| 종류 | 의미 | 사용예 |
|---|---|---|
| LENGTH | 문자열의 길이를 반환 | LENGTH('홍길동') -> 3 |
| LENGTHB | 문자열의 바이트 수를 반환 | LENGTHB('홍길동') -> 6 |
문자 조작 함수[편집 | 원본 편집]
| 종류 | 의미 | 사용예 |
|---|---|---|
| CONCAT | 두 문자열을 결합. ||와 동일 | CONCAT('sql','plus') -> sqlplus |
| SUBSTR | 특정 문자 또는 문자열 일부를 추출 | SUBSTR('SQL*PLUS',5,4) -> PLUS |
| INSTR | 특정 문자가 출현하는 첫번째 위치 반환 | INSTR('SQL*Plus','*',1,1) -> 4 |
| LPAD | 오른쪽 정렬 후 왼쪽에 지정한 문자 삽입 | LPAD('sql',5,'*') -> **sql |
| RPAD | 왼쪽 정렬 후 오른쪽에 지정한 문자 삽입 | RPAD('sql',5,'*') -> sql** |
| LTRIM | 왼쪽의 지정 문자를 삭제 | LTRIM('*sql','*') -> sql |
| RTRIM | 오른쪽의 지정 문자를 삭제 | RTRIM('sql*','*') -> sql |
숫자 함수[편집 | 원본 편집]
| 종류 | 의미 | 사용예 |
|---|---|---|
| ROUND | 지정한 자리 이하에서 반올림 | ROUND(123.17,1) -> 123.2 |
| TRUNC | 지정한 자리 이하에서 절삭(버림) | TRUNC(123.17,1) -> 123.1 |
| MOD(m, n) | m을 n으로 나눈 나머지 값 | MOD(12,10) -> 2 |
| CEIL | 지정한 값보다 큰 수 중에서 가장 작은 정수 | CEIL(123.17) -> 124 |
| FLOOR | 지정한 값보다 작은 수 중에서 가장 큰 정수 | FLOOR(123.17) -> 123 |
날짜 함수[편집 | 원본 편집]
| 종류 | 의미 | 결과 |
|---|---|---|
| SYSDATE | 시스템의 현재 날짜 | 날짜 |
| MONTHS_BETWEEN | 날짜와 날짜 사이의 개월을 계산 | 숫자 |
| ADD_MONTHS | 날짜에 개월을 더한 날짜 계산 | 날짜 |
| NEXT_DAY | 날짜 후의 첫 월요일 날짜를 계산 | 날짜 |
| LAST_DAY | 월의 마지막 날짜를 계산 | 날짜 |
| ROUND | 날짜를 반올림 | 날짜 |
| TRUNC | 날짜를 절삭 | 날짜 |
형변환[편집 | 원본 편집]
| 종류 | 의미 | 사용예 | 결과 |
|---|---|---|---|
| TO_CHAR | 숫자, 날짜를 문자타입으로 | TO_CHAR('07-12', 'YYYY-MM') | 2007-12 |
| TO_NUMBER | 문자열을 숫자타입으로 | TO_NUMBER('1000') | 1,000 |
| TO_DATE | 문자열을 날짜타입으로 | TO_DATE('05/03', 'YYYY-MM') | 0005-03 |