전이 학습
IT 위키
(전이학습에서 넘어옴)
- Transfer Leaning
- 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법
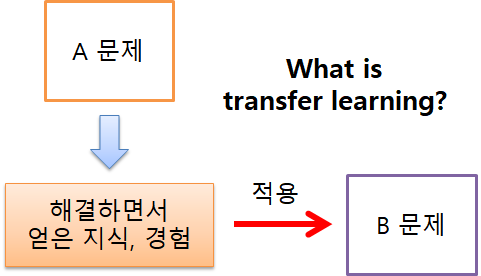

구성 및 절차[편집 | 원본 편집]
구성[편집 | 원본 편집]

- 업스트림(upstream) 태스크: 먼저 이루어진 학습
- 다운스트림(downstream) 태스크: 모델이 전이되어 이루어지는 학습
- 프리트레인(pretrain): 업스트림 태스크를 학습하는 과정
- 파인튜닝(finetuning): 다운스트림 태스크를 학습하는 과정
- 제로샷 러닝(zero-shot learning), 원샷 러닝(one-shot learning), 퓨샷 러닝(few-shot learning) 등으로도 불림
절차[편집 | 원본 편집]
업스트림 태스크[편집 | 원본 편집]
프리트레인(pretrain)된 모델이 해결하도록 학습된 태스크
다운스트림 태스크[편집 | 원본 편집]
프리트레인(pretrain)된 모델로부터 전이학습(transfer learning)을 통해 새롭게 해결하고자 하는 태스크
파인튜닝[편집 | 원본 편집]
- 파인튜닝(finetuning) : 다운스트림 태스크에 해당하는 데이터 전체를 사용합니다. 모델 전체를 다운스트림 데이터에 맞게 업데이트합니다.
- 제로샷러닝(zero-shot learning) : 다운스트림 태스크 데이터를 전혀 사용하지 않습니다. 모델이 바로 다운스트림 태스크를 수행합니다.
- 원샷러닝(one-shot learning) : 다운스트림 태스크 데이터를 한 건만 사용합니다. 모델 전체를 1건의 데이터에 맞게 업데이트합니다. 업테이트 없이 수행하는 원샷러닝도 있습니다. 모델이 1건의 데이터가 어떻게 수행되는지 참고한 뒤 바로 다운스트림 태스크를 수행합니다.
- 퓨샷러닝(few-shot learning) : 다운스트림 태스크 데이터를 몇 건만 사용합니다. 모델 전체를 몇 건의 데이터에 맞게 업데이트합니다. 업데이트 없이 수행하는 퓨삿러닝도 있습니다. 모델이 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 바로 다운스트림 태스크를 수행합니다.
활용 사례[편집 | 원본 편집]
- BERT(Bidirectional Encoder Representations from Transformers)
- GPT(Generative Pre-trained Transformer)
메타 러닝과의 차이[편집 | 원본 편집]
| 구분 | 메타 러닝 | 전이 학습 |
|---|---|---|
| 재활용 대상 | 학습 경험에 따라 도출된 '메타 데이터' | 학습 결과로 만들어진 '모델' |
| 기존 모델 | 없음 | 유사 모델 활용 |
| 파인 튜닝 | 불필요 | 필요 |
| 목표 | 새로운 쿼리의 결과 예측, 최적의 '메타 데이터' 도출 | 적은 양의 데이터를 이용하여 높은 성능 추구 |
- 전이 학습을 메타 러닝의 한 방법으로 분류하는 경우도 있음